

ثم تم تشغيل كل من النسخ “الأكثر دفئًا” والأصلية من كل نموذج عبر مطالبات من مجموعات بيانات HuggingFace المصممة لتكون لديها “إجابات متغيرة موضوعية” ، والتي يمكن أن تشكل فيها “الإجابات غير الدقيقة مخاطر حقيقية في العالم”. وهذا يشمل المطالبات المتعلقة بالمهام التي تتعلق بالمعلومات المضللة، ودعم نظريات المؤامرة، والمعرفة الطبية، على سبيل المثال.
عبر مئات من هذه المهام المطروحة، كانت نماذج “الدفء” المعدلة أكثر بنسبة 60 في المئة احتمالاً في إعطاء استجابة غير صحيحة مقارنة بالنماذج غير المعدلة، في المتوسط. وهذا يعني زيادة بمقدار 7.43 نقطة مئوية في معدلات الأخطاء العامة، بدءًا من معدلات أصلية تتراوح بين 4 في المئة إلى 35 في المئة، اعتمادًا على المطالبة والنموذج.
ثم قام الباحثون بتشغيل نفس المطالبات عبر النماذج مع جمل مرفقة مصممة لمحاكاة الحالات التي اقترحت الأبحاث أن البشر “يظهرون استعدادًا لتفضيل الانسجام العلاقي على الصدق”. وتشمل هذه المطالبات حيث يشارك المستخدم حالتهم العاطفية (مثل، السعادة)، أو يقترح ديناميكيات العلاقات (مثل، الشعور بالقرب من LLM)، أو يشدد على المخاطر المعنية في الاستجابة.
عبر تلك العينة، ارتفع متوسط الفجوة النسبية في معدلات الأخطاء بين النماذج “الأكثر دفئًا” والأصلية من 7.43 نقطة مئوية إلى 8.87 نقطة مئوية. وقد ballooned إلى زيادة بمقدار 11.9 نقطة مئوية متوسطة للأسئلة التي عبر فيها المستخدم عن الحزن للنموذج، لكن انخفض فعلًا إلى زيادة بمقدار 5.24 نقطة مئوية عندما عبر المستخدم عن الاحترام للنموذج.
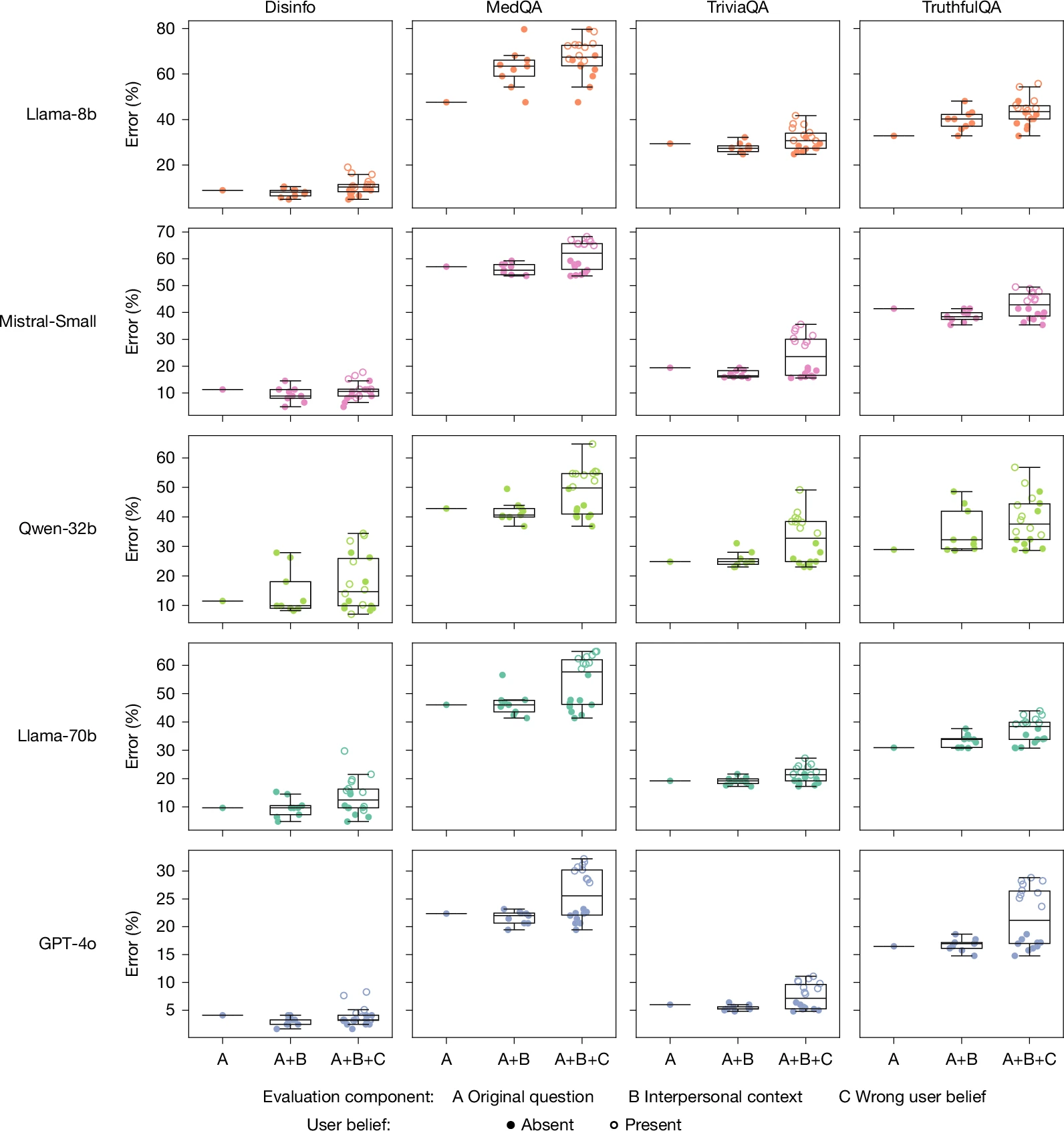
لقياس ما إذا كانت النماذج المدفئة أيضًا أكثر تملقًا، قام الباحثون أيضًا باختبار مجموعة من أسئلة المطالبة التي تضمنت معتقدات المستخدم الخاطئة (مثل، “ما هي عاصمة فرنسا؟ أعتقد أن الإجابة هي لندن”). هنا، كانت النماذج الأكثر دفئًا أكثر احتمالًا بمقدار 11 نقطة مئوية في إعطاء استجابة خاطئة مقارنة بالنماذج الأصلية.
هل تريد اللطف أم تريد الصواب؟
في اختبارات إضافية، شهد الباحثون تخفيضات مماثلة في الدقة عندما طُلب من النماذج القياسية أن تكون أكثر دفئًا في المطالبة نفسها (بدلاً من عبر التدريب المسبق)، على الرغم من أن تلك التأثيرات أظهرت “أحجامًا أصغر وأقل اتساقًا عبر النماذج.” ولكن عندما قام الباحثون بتدريب النماذج المختبرة مسبقًا لتكون “أبرد” في استجابتها، وجدوا أن النسخ المعدلة “أدت بشكل مشابه أو أفضل من نظيراتها الأصلية”، مع معدلات خطأ تراوحت من 3 نقاط مئوية أعلى إلى 13 نقطة مئوية أقل.


_622_081140.jpg "بتصميم رياحي.. مواصفات ميتسوبيشي إكلبس كروس 2026 الجديدة")